2026数智化报告 04 | 标准驱动:构建数据治理体系,释放数据资产价值
本期聚焦数据标准、质量、安全与资产管理,解析如何构建财务数据治理体系,释放企业数据价值。
《2026年财务数智化转型升级白皮书》由中兴新云、北京国家会计学院联合发布,以“五个驱动”与“五个升级”为核心框架,深度解读财务数智化转型的时代背景、内涵要义与落地路径,覆盖价值管理、系统建设、数据治理、穿透监管、流程再造与转型规划等关键领域。围绕以上核心议题,我们将通过系列文章分期解读,逐一探讨。本期内容聚焦——财务信息数字化升级,从建立数据治理体系与深度挖掘数据价值展开。
随着企业财务管理职能不断向支撑战略、赋能业务、注智管理拓展,财务需要能够对内外部数据进行智能化采集、处理和分析,利用数据驱动决策和服务创新。然而在数据应用过程中,企业在数据治理方面仍面临一些挑战,如数据质量不佳、数据缺乏统一标准、数据安全难以保障等。为此,企业需统一制定数据标准,建立数据治理体系,打通数据采集、清洗、整合、分析、应用的数据价值链全过程,深度挖掘数据价值。
建立数据治理体系
数据标准为数据在“采、存、管、算、用”的全生命周期中提供统一遵循,确保数据的准确性、一致性与可比性,是数据治理体系的核心基石,其他数据治理活动的开展均需遵循数据标准的统一规范。然而企业信息化建设初期,往往将管理重心放在系统建设和业务发展中,忽视数据标准管理,导致企业中存在各业务系统、各分子公司之间数据定义各异、统计口径不一、编码规则混乱等问题,横向业财数据难以整合贯通,纵向集团层面更是难以对下属单位层层穿透、形成精准的监管视图,数据价值难以被有效挖掘。
基于数据标准管理的重要性和必要性,财务数智化文件将数据标准内容从数据治理体系中独立出来,详细展开具体要求。国内外相关机构已提出多种数据治理标准与模型,为企业数据治理体系的建设提供重要理论基础。
根据《数据管理能力成熟度评估模型》(GB/T 36073-2025)中对数据治理的定义:数据治理是组织提升数据的质量、安全和合规性,推动数据有效利用的过程。根据国内外数据治理方法论,可以看出企业数据治理建设通常包括数据治理组织、数据治理制度、数据治理流程、元数据管理、主数据管理、数据标准管理、数据质量管理、数据安全管理、数据资产管理等内容。
一、数据标准管理
数据标准是通过统一规范数据的命名、数据类型、数据长度、业务含义、计算口径、归属部门等,保障数据内外部使用和交换的一致性和准确性的规范性约束。根据大数据技术标准推进委员会近期发布的《数据标准管理实践指南(2.0 版)》,数据标准按照管理对象可划分为:
- 基础类数据标准:对业务流程中直接产生的,未经过加工和处理的基础业务信息进行标准化后形成的定义规范,如对客户数据、产品数据、员工数据、财务数据等进行统一规范。
- 应用类数据标准:针对特定业务场景、业务流程、分析需求而制定的数据规范,包括指标类数据标准、标签类数据标准、 主数据标准。以指标类数据标准为例,如监管合规类指标标准、营销管理类指标标准、风险管理类指标标准、资金管理类指标标准等。
- 资产类数据标准:从将数据作为资产进行管理和运营的角度出发,为实现数据资产的可理解、可复用、可流通而制定的标准体系,如数据模型标准、数据产品标准、数据字典标准等。
从具体内容来看,数据标准管理通常包含对数据的业务属性、技术属性、管理属性进行标准化:

▲ 数据标准管理内容
二、元数据管理
元数据是指描述数据的数据,包括业务元数据、技术元数据和操作元数据。元数据管理通过对企业数据的产生、处理和流动进行记录与监控,打造数据血缘探查能力,及时发现数据不准确、不一致等问题产生的原因,帮助企业稽核数据质量。例如,数据血缘通过清晰描绘数据从源头到最终报表的完整流动路径、转换逻辑和依赖关系,当总账与子模块、业务系统与财务系统、或者不同报表之间出现数据不一致的情况时,数据血缘能够迅速定位差异发生的具体环节,并确保分析数据的准确性与一致性。
财务数智化文件中提及的元数据血缘图谱,是指利用图数据库、构建数据映射关系等方式实现对元数据血缘关系的存储与可视化展示,进而提高数据的关联性、 透明性和可追溯性。
三、主数据管理
主数据是指满足组织跨部门业务协同需要的、反映核心业务实体状态属性的基础信息,具有跨越部门、跨越业务、跨越流程、跨越系统、跨越技术等特征。从主数据描述的实体类型来看,企业典型的主数据一般包括供应商、客户、组织、人员、 产品、物料、财务等实体的基础信息。
企业缺乏有效的主数据管理,客户、产品、供应商等同一实体,在财务与业务的不同系统、不同流程中,会出现标识不一致、定义不一致、计算逻辑不一致等数据问题,导致企业内数据映射关系复杂,产生较高的数据交互和数据共享成本。
通过开展有效的主数据管理,企业可确保主数据的共享性、一致性、准确性与完整性。首先,通过对企业内核心实体的主数据进行全面识别与梳理,评估当前主数据管理成熟度。其次,确定数据Owner,由数据Owner作为某一具体领域主数据治理的“第一责任人”,根据主数据评估结果制定主数据管理体系,包括确定该领域主数据治理的目标、工作计划及执行优先级,设计该领域主数据质量标准, 承接内外部主数据共享需求。
从财务视角来看,核算、资金、税务等财务领域主数据是需要财务作为数据 Owner去管理的主数据,客户、供应商、组织、人员、产品、物料等领域的主数据会对财务工作产生影响,是需要财务积极推动其他部门管理的主数据。
四、数据质量管理
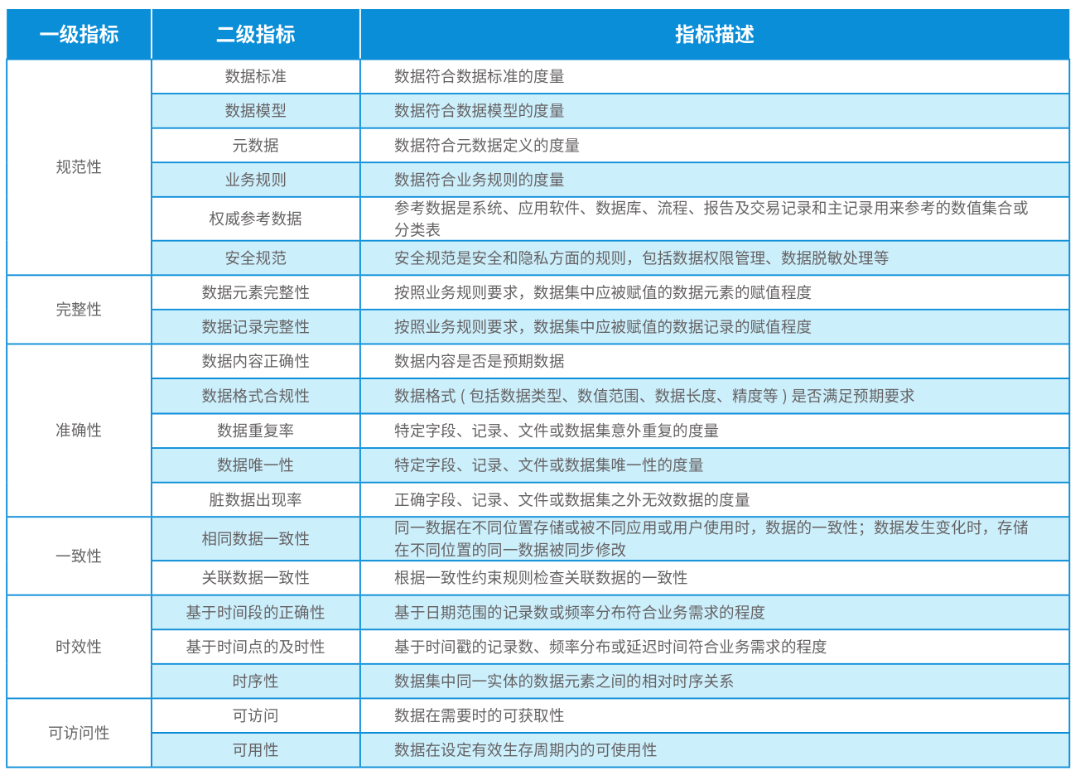 ▲ 数据质量评价指标(GB/T 36344-2018)
▲ 数据质量评价指标(GB/T 36344-2018)
数据以产品或服务的形态为企业创造价值,高质量数据是一切数据应用的基础,是数据发挥价值的前提。财务部门涉及大量的报表出具和数据分析工作,如合并报表编制和出具、 各类管理报表、监管数据报送等,需要汇聚不同分析场景、 不同部门以及多个下属单位的数据,如果数据质量不佳,将耗费大量人力进行数据清洗与加工,严重影响数据处理效率和准确性。根据国家标准《GB/T 36344-2018信息技术数据质量评价指标》,企业数据质量情况可从规范性、完整性、 准确性、一致性、时效性、可访问性等方面进行衡量。
数据质量管理并非仅是事后检查,而是一套贯穿数据“采、 存、管、算、用”全生命周期的质量管控体系。企业应遵循 “谁产生数据,谁对数据质量负责”的原则,构建“数据质量需求定义—数据质量规则制定—数据质量稽核执行—数据质量问题整改—数据质量评价优化”的数据质量闭环管理机制,以及实时与定期相结合的数据质量监控机制。在具体管控过程中,通过自动化工具对关键数据质量指标进行持续监测,及时发现异常并推动整改与反馈,保障数据在全生命周期内均能满足业务需求与合规要求,达成“产生即规范,生成即可用”的数据质量管理目标。
五、数据安全管理
2024年财政部印发的《会计信息化工作规范》(财会 〔2024〕11号)明确提出,单位应当加强会计数据安全风险防范,采取数据加密传输技术等有效措施,保证会计数据处理与应用的安全合规,避免会计数据在生成、传输、处理、 存储等环节的泄露、篡改及损毁风险。世界一流财务管理文件明确指出,企业在完善智能前瞻的财务数智体系过程中, 要加强系统、平台、数据安全管理,筑牢安全防护体系。财务数智化文件要求,企业需建立健全数据全生命周期安全防护体系,明确数据分级分类管理要求,增强数据安全风险识别、防控与处置能力,实现数据治理全程合规、全域安全。
数据安全管理的核心目标是保证企业内部数据安全有序地在各层级、各部门之间的流转与应用,实现对隐私、保密制度、 法规的遵从,满足利益相关方的隐私和保密要求。企业需基于自身数据安全管理需求与监管合规要求,在明确企业数据分类分级管理结果的基础之上,评估企业面临的各种数据安全风险,并搭建数据安全管理体系,部署数据安全基础设施, 监控数据在全生命周期各环节的安全、隐私及合规状况,保证数据在全生命周期内的可用性、完整性、保密性以及合规性。
六、数据资产管理

▲ 数据资产目录建设示意
2023年12月,财政部印发《关于加强数据资产管理的指导意见》(财资〔2023〕141号),明确提出鼓励数据资产持有主体提升数据资产数字化管理能力。面对企业沉积的海量数据资产,企业应积极推动建立企业数据资产目录,以全面梳理与明确企业所拥有的数据资产,进而支撑数据的有效展示、系统记录与深入分析,为数据资产的确权、流转和价值实现提供基础。
企业数据资产目录建设可分为五个层次。L1主题域分组,从数据视角体现公司最高层面关注的业务领域。L2主题域,根据业务的关注点,将联系较为紧密的数据主题划分至不同的主题域,不同主题域之间互不重叠,但各主题之间允许交叉,一般可按照系统模块、业务流程、部门等不同维度划分主题域。L3业务对象,承载业务运作和管理涉及的重要信息,包括实体、过程、事件三类业务对象。 L4逻辑实体,描述业务对象某种业务特征属性的集合。L5属性,描述所属业务对象的性质和特征。
深度挖掘数据价值
企业通过数据治理沉淀高质量数据资产之后,需进一步发挥数据优势,面向业务需求,贯通数据价值链全过程,打通企业数据流转链路,构建标准化数据服务架构,进而有针对性地提取、组织并利用数据,实现对多源异构数据跨领域、跨层级、跨部门的实时采集、融合加工、模型计算、自助分析、共享复用,盘活数据资产、发挥数据价值。
一、数据采集
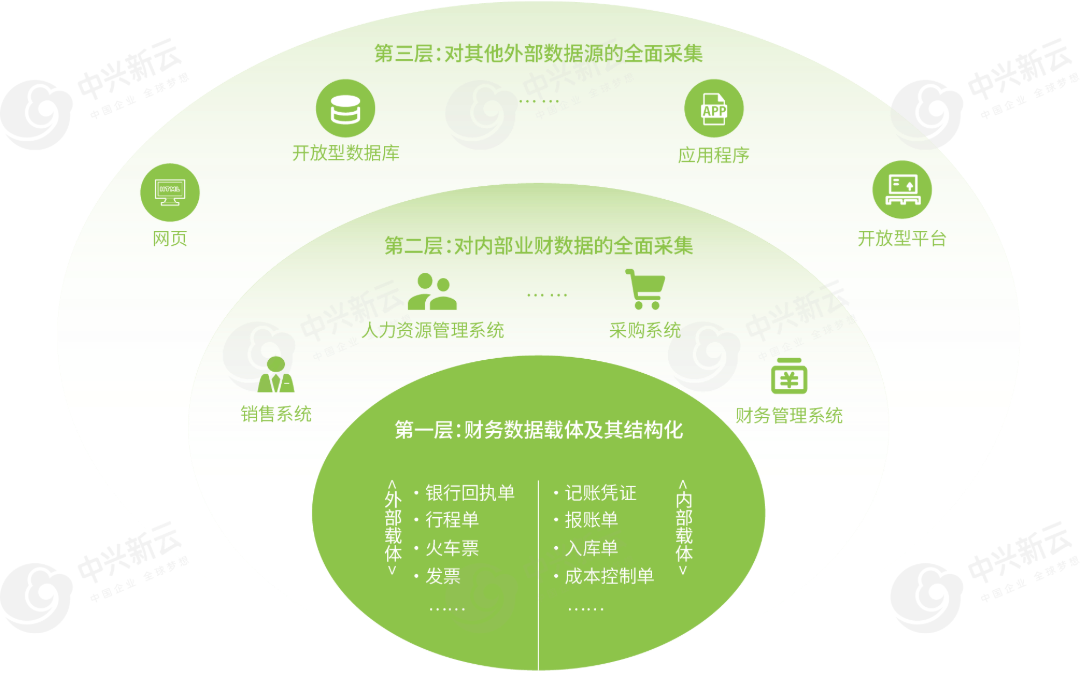
▲ 数据采集的三个层次
过去,财务部门的核心职能主要集中在核算和财务报告的生成上,其数据来源和处理方式相对单一且局限。随着企业业务规模的扩大、信息技术的进步以及财务职能的拓展,财务关注的数据范围逐渐从传统财务数据采集拓展到企业内外部数据的全面采集。
具体来看,财务数据采集范围可总结为三个层次。第一层是财务数据载体,包括承载业务处理过程中所形成的各种结果数据的单据或票证,是财务开展核算工作的重要依据;第二层是企业内部业财系统数据,广泛采集研发、采购、生产、销售等业务环节相关系统的数据,进一步支持企业控制、预测、管理活动的开展;第三层是外部数据源,包括网页、应用程序、外部开放型数据库等相关客情、竞情、行情、国情等数据。
二、数据清洗
数据清洗是处理脏数据的过程,通过数据清洗可为高质效的数据分析工作和高效能的算法模型训练提供可信可用的数据输入,满足各方面“取数、用数”需要。传统数据清洗工作主要依靠手工进行,庞大的数据规模给数据清洗工作带来严峻挑战,数据清洗的人力和时间投入持续增加,清洗结果却并不理想。随着数智化技术发展,算法模型在数据清洗中的应用愈加成熟与普遍,帮助企业大幅提升数据清洗效率、降低数据清洗成本、提高数据清洗质量。
企业可将数据清洗目标与数据质量问题定义规则内嵌算法模型中,批量校验数据集中是否存在数据缺失或重复、数值异常或错误、格式不规范一致等数据质量问题,并自动依据数据质量识别分析结果选择合适的数据清洗规则和策略。例如, 通过执行格式清洗、空值填充、数据排序、删除重复数据及字段类型转换等数据清洗策略,自动处理数据集中存在的数据质量问题。
三、数据加工
数据加工旨在描述数据特征、发现数据规律、挖掘数据价值。财务借助数据工厂、APA(Analytic Process Automation,分析流程自动化)等工具,通过可视化拖拉拽的操作方式开展数据自由组合、灵活配置,快速进行数据汇聚、数据清洗、数据标注、模型搭建及场景应用,将数据转化为有效的洞察、分析、决策依据或新型服务,驱动业务优化与价值创造。在此过程中, 指标、标签、算法、模型等是满足数据加工、分析需求的核心要素。
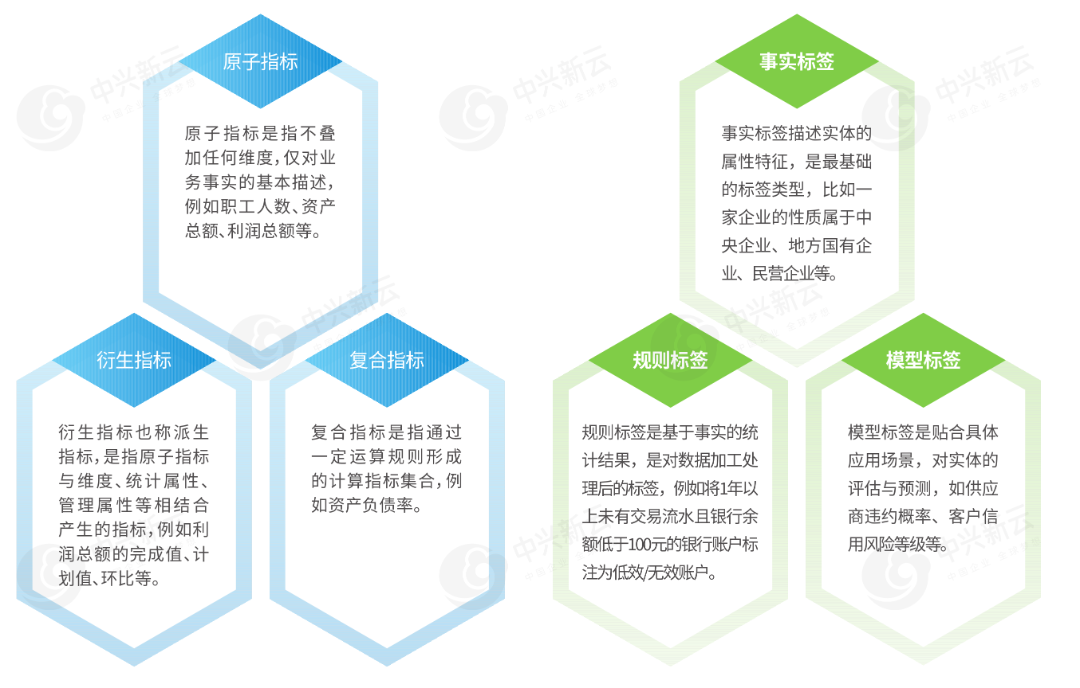
▲ 指标分类、标签分类
- 指标:是量化客观事物的具体数值。指标的分类相对固定,一般分为原子指标、衍生指标和复合指标三类。
- 标签:是描述客观事物特征的定性标识,用于差异化管理和决策。标签通常描述某些具体实体,一般可分为事实标签、规则标签和模型标签。
- 算法:是一系列明确的、用于解决特定问题或执行计算的步骤指令,是加工计算、处理数据的过程,用于告诉模型应如何去学习和做出判断,如回归算法、分类算法、时间序列算法等。
- 模型:是对现实世界业务分析需求的简化表示或抽象, 由数据、规则、算法、参数、阈值等共同组成,用于描述、预测、优化现实问题。如过度负债模型、虚假贸易模型、财务指标异常预警模型等。
四、数据可视化
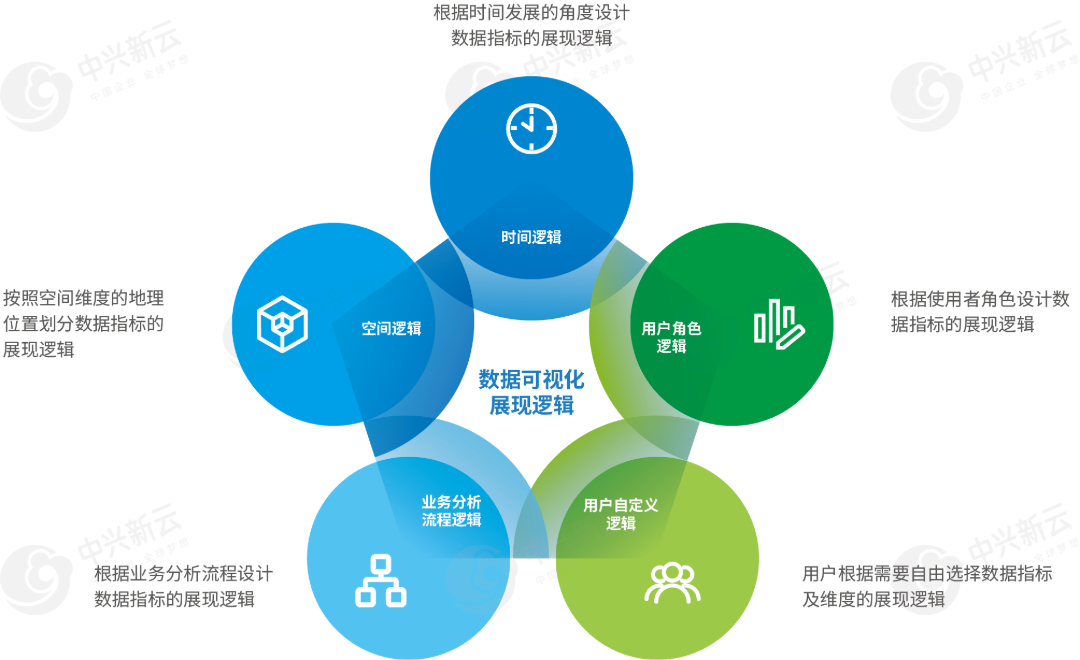
▲ 数据可视化展示逻辑
数据可视化综合运用计算机图形学、图像处理、人机交互等技术,将数据内涵及数据分析结果转化为可视大屏、BI看板、 图文报告、表格报表等展示形式,帮助用户快速理解数据之间的趋势和关系,提取有价值的洞察和见解。
数据可视化展现应以用户为中心,采用适宜的数据展现逻辑 和可视化图表传递数据分析结果,帮助用户从海量数据中迅速获得所需信息。
成功的数据可视化设计需遵循四方面设计原则:第一,运用先验知识,基于对用户行为与期望的预测进行设计,提升用户理解效率,增强可视化成果的可用性;第二,匹配恰当的视图与交互,根据数据的复杂程度与期望传递的信息,选用单一基础视图或组合多种视图,并辅以恰当的交互设计;第三,控制信息密度,合理规划单视图的信息承载量,避免信息过载,确保核心信息能被快速捕捉;第四,融入美学设计, 追求功能性与形式美的平衡,通过良好的视觉呈现提升整体表达效果。

